Argo meta-data#
Index of profiles#
Since the Argo measurements dataset is quite complex, it comes with a collection of index files, or lookup tables with meta data. These index help you determine what you can expect before retrieving the full set of measurements. argopy has a specific fetcher for index files:
In [1]: from argopy import IndexFetcher as ArgoIndexFetcher
You can use the Index fetcher with the region or float access points, similarly to data fetching:
In [2]: idx = ArgoIndexFetcher(src='gdac').float(2901623).load()
In [3]: idx.index
Out[3]:
file ... profiler
0 nmdis/2901623/profiles/R2901623_000.nc ... Provor, Seabird conductivity sensor
1 nmdis/2901623/profiles/R2901623_000D.nc ... Provor, Seabird conductivity sensor
2 nmdis/2901623/profiles/R2901623_001.nc ... Provor, Seabird conductivity sensor
3 nmdis/2901623/profiles/R2901623_002.nc ... Provor, Seabird conductivity sensor
4 nmdis/2901623/profiles/R2901623_003.nc ... Provor, Seabird conductivity sensor
.. ... ... ...
93 nmdis/2901623/profiles/R2901623_092.nc ... Provor, Seabird conductivity sensor
94 nmdis/2901623/profiles/R2901623_093.nc ... Provor, Seabird conductivity sensor
95 nmdis/2901623/profiles/R2901623_094.nc ... Provor, Seabird conductivity sensor
96 nmdis/2901623/profiles/R2901623_095.nc ... Provor, Seabird conductivity sensor
97 nmdis/2901623/profiles/R2901623_096.nc ... Provor, Seabird conductivity sensor
[98 rows x 11 columns]
Alternatively, you can use argopy.IndexFetcher.to_dataframe():
In [4]: idx = ArgoIndexFetcher(src='gdac').float(2901623)
In [5]: df = idx.to_dataframe()
The difference is that with the load method, data are stored in memory and not fetched on every call to the index attribute.
The index fetcher has pretty much the same methods than the data fetchers. you can check them all here: argopy.fetchers.ArgoIndexFetcher.
Reference tables#
The Argo netcdf format is strict and based on a collection of variables fully documented and conventioned. All reference tables can be found in the Argo user manual.
However, a machine-to-machine access to these tables is often required. This is possible thanks to the work of the Argo Vocabulary Task Team (AVTT) that is a team of people responsible for the NVS collections under the Argo Data Management Team governance.
Note
The GitHub organization hosting the AVTT is the ‘NERC Vocabulary Server (NVS)’, aka ‘nvs-vocabs’. This holds a list of NVS collection-specific GitHub repositories. Each Argo GitHub repository is called after its corresponding collection ID (e.g. R01, RR2, R03 etc.). The current list is given here.
The management of issues related to vocabularies managed by the Argo Data Management Team is done on this repository.
argopy provides the utility class ArgoNVSReferenceTables to easily fetch and get access to all Argo reference tables. If you already know the name of the reference table you want to retrieve, you can simply get it like this:
In [6]: from argopy import ArgoNVSReferenceTables
In [7]: NVS = ArgoNVSReferenceTables()
In [8]: NVS.tbl('R01')
Out[8]:
altLabel ... id
0 BPROF ... http://vocab.nerc.ac.uk/collection/R01/current...
1 BTRAJ ... http://vocab.nerc.ac.uk/collection/R01/current...
2 META ... http://vocab.nerc.ac.uk/collection/R01/current...
3 MPROF ... http://vocab.nerc.ac.uk/collection/R01/current...
4 MTRAJ ... http://vocab.nerc.ac.uk/collection/R01/current...
5 PROF ... http://vocab.nerc.ac.uk/collection/R01/current...
6 SPROF ... http://vocab.nerc.ac.uk/collection/R01/current...
7 TECH ... http://vocab.nerc.ac.uk/collection/R01/current...
8 TRAJ ... http://vocab.nerc.ac.uk/collection/R01/current...
[9 rows x 5 columns]
The reference table is returned as a pandas.DataFrame. If you want the exact name of this table:
In [9]: NVS.tbl_name('R01')
Out[9]:
('DATA_TYPE',
'Terms describing the type of data contained in an Argo netCDF file. Argo netCDF variable DATA_TYPE is populated by R01 prefLabel.',
'http://vocab.nerc.ac.uk/collection/R01/current/')
On the other hand, if you want to retrieve all reference tables, you can do it with the ArgoNVSReferenceTables.all_tbl() method. It will return a dictionary with table short names as key and pandas.DataFrame as values.
In [10]: all = NVS.all_tbl()
In [11]: all.keys()
Out[11]: odict_keys(['ARGO_WMO_INST_TYPE', 'CYCLE_TIMING_VARIABLE', 'DATA_CENTRE_CODES', 'DATA_STATE_INDICATOR', 'DATA_TYPE', 'DM_QC_FLAG', 'GROUNDED', 'HISTORY_ACTION', 'HISTORY_STEP', 'MEASUREMENT_CODE_CATEGORY', 'MEASUREMENT_CODE_ID', 'OCEAN_CODE', 'PARAMETER', 'PLATFORM_FAMILY', 'PLATFORM_MAKER', 'PLATFORM_TYPE', 'POSITIONING_SYSTEM', 'POSITION_ACCURACY', 'PROF_QC_FLAG', 'REPRESENTATIVE_PARK_PRESSURE_STATUS', 'RTQC_TESTID', 'RT_QC_FLAG', 'SENSOR', 'SENSOR_MAKER', 'SENSOR_MODEL', 'STATUS', 'TRANS_SYSTEM', 'VERTICAL_SAMPLING_SCHEME'])
Deployment Plan#
It may be useful to be able to retrieve meta-data from Argo deployments. argopy can use the OceanOPS API for metadata access to retrieve these information. The returned deployment plan is a list of all Argo floats ever deployed, together with their deployment location, date, WMO, program, country, float model and current status.
To fetch the Argo deployment plan, argopy provides a dedicated utility class: OceanOPSDeployments that can be used like this:
In [12]: from argopy import OceanOPSDeployments
In [13]: deployment = OceanOPSDeployments()
In [14]: df = deployment.to_dataframe()
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Cell In[14], line 1
----> 1 df = deployment.to_dataframe()
File ~/checkouts/readthedocs.org/user_builds/argopy/checkouts/v0.1.13/argopy/utilities.py:3384, in OceanOPSDeployments.to_dataframe(self)
3380 # if status[ptf['ptfStatus']['name']] is None:
3381 # status[ptf['ptfStatus']['name']] = ptf['ptfStatus']['description']
3383 df = pd.DataFrame(res)
-> 3384 df = df.astype({'date': np.datetime64})
3385 df = df.sort_values(by='date').reset_index(drop=True)
3386 # df = df[ (df['status_name'] == 'CLOSED') | (df['status_name'] == 'OPERATIONAL')] # Select only floats that have been deployed and returned data
3387 # print(status)
File ~/checkouts/readthedocs.org/user_builds/argopy/envs/v0.1.13/lib/python3.8/site-packages/pandas/core/generic.py:6305, in NDFrame.astype(self, dtype, copy, errors)
6303 else:
6304 try:
-> 6305 res_col = col.astype(dtype=cdt, copy=copy, errors=errors)
6306 except ValueError as ex:
6307 ex.args = (
6308 f"{ex}: Error while type casting for column '{col_name}'",
6309 )
File ~/checkouts/readthedocs.org/user_builds/argopy/envs/v0.1.13/lib/python3.8/site-packages/pandas/core/generic.py:6324, in NDFrame.astype(self, dtype, copy, errors)
6317 results = [
6318 self.iloc[:, i].astype(dtype, copy=copy)
6319 for i in range(len(self.columns))
6320 ]
6322 else:
6323 # else, only a single dtype is given
-> 6324 new_data = self._mgr.astype(dtype=dtype, copy=copy, errors=errors)
6325 return self._constructor(new_data).__finalize__(self, method="astype")
6327 # GH 33113: handle empty frame or series
File ~/checkouts/readthedocs.org/user_builds/argopy/envs/v0.1.13/lib/python3.8/site-packages/pandas/core/internals/managers.py:451, in BaseBlockManager.astype(self, dtype, copy, errors)
448 elif using_copy_on_write():
449 copy = False
--> 451 return self.apply(
452 "astype",
453 dtype=dtype,
454 copy=copy,
455 errors=errors,
456 using_cow=using_copy_on_write(),
457 )
File ~/checkouts/readthedocs.org/user_builds/argopy/envs/v0.1.13/lib/python3.8/site-packages/pandas/core/internals/managers.py:352, in BaseBlockManager.apply(self, f, align_keys, **kwargs)
350 applied = b.apply(f, **kwargs)
351 else:
--> 352 applied = getattr(b, f)(**kwargs)
353 result_blocks = extend_blocks(applied, result_blocks)
355 out = type(self).from_blocks(result_blocks, self.axes)
File ~/checkouts/readthedocs.org/user_builds/argopy/envs/v0.1.13/lib/python3.8/site-packages/pandas/core/internals/blocks.py:511, in Block.astype(self, dtype, copy, errors, using_cow)
491 """
492 Coerce to the new dtype.
493
(...)
507 Block
508 """
509 values = self.values
--> 511 new_values = astype_array_safe(values, dtype, copy=copy, errors=errors)
513 new_values = maybe_coerce_values(new_values)
515 refs = None
File ~/checkouts/readthedocs.org/user_builds/argopy/envs/v0.1.13/lib/python3.8/site-packages/pandas/core/dtypes/astype.py:242, in astype_array_safe(values, dtype, copy, errors)
239 dtype = dtype.numpy_dtype
241 try:
--> 242 new_values = astype_array(values, dtype, copy=copy)
243 except (ValueError, TypeError):
244 # e.g. _astype_nansafe can fail on object-dtype of strings
245 # trying to convert to float
246 if errors == "ignore":
File ~/checkouts/readthedocs.org/user_builds/argopy/envs/v0.1.13/lib/python3.8/site-packages/pandas/core/dtypes/astype.py:187, in astype_array(values, dtype, copy)
184 values = values.astype(dtype, copy=copy)
186 else:
--> 187 values = _astype_nansafe(values, dtype, copy=copy)
189 # in pandas we don't store numpy str dtypes, so convert to object
190 if isinstance(dtype, np.dtype) and issubclass(values.dtype.type, str):
File ~/checkouts/readthedocs.org/user_builds/argopy/envs/v0.1.13/lib/python3.8/site-packages/pandas/core/dtypes/astype.py:116, in _astype_nansafe(arr, dtype, copy, skipna)
114 dti = to_datetime(arr.ravel())
115 dta = dti._data.reshape(arr.shape)
--> 116 return dta.astype(dtype, copy=False)._ndarray
118 elif is_timedelta64_dtype(dtype):
119 from pandas.core.construction import ensure_wrapped_if_datetimelike
File ~/checkouts/readthedocs.org/user_builds/argopy/envs/v0.1.13/lib/python3.8/site-packages/pandas/core/arrays/datetimes.py:694, in DatetimeArray.astype(self, dtype, copy)
682 raise TypeError(
683 "Cannot use .astype to convert from timezone-aware dtype to "
684 "timezone-naive dtype. Use obj.tz_localize(None) or "
685 "obj.tz_convert('UTC').tz_localize(None) instead."
686 )
688 elif (
689 self.tz is None
690 and is_datetime64_dtype(dtype)
691 and dtype != self.dtype
692 and is_unitless(dtype)
693 ):
--> 694 raise TypeError(
695 "Casting to unit-less dtype 'datetime64' is not supported. "
696 "Pass e.g. 'datetime64[ns]' instead."
697 )
699 elif is_period_dtype(dtype):
700 return self.to_period(freq=dtype.freq)
TypeError: Casting to unit-less dtype 'datetime64' is not supported. Pass e.g. 'datetime64[ns]' instead.
In [15]: df
Out[15]:
file ... profiler
0 nmdis/2901623/profiles/R2901623_000.nc ... Provor, Seabird conductivity sensor
1 nmdis/2901623/profiles/R2901623_000D.nc ... Provor, Seabird conductivity sensor
2 nmdis/2901623/profiles/R2901623_001.nc ... Provor, Seabird conductivity sensor
3 nmdis/2901623/profiles/R2901623_002.nc ... Provor, Seabird conductivity sensor
4 nmdis/2901623/profiles/R2901623_003.nc ... Provor, Seabird conductivity sensor
.. ... ... ...
93 nmdis/2901623/profiles/R2901623_092.nc ... Provor, Seabird conductivity sensor
94 nmdis/2901623/profiles/R2901623_093.nc ... Provor, Seabird conductivity sensor
95 nmdis/2901623/profiles/R2901623_094.nc ... Provor, Seabird conductivity sensor
96 nmdis/2901623/profiles/R2901623_095.nc ... Provor, Seabird conductivity sensor
97 nmdis/2901623/profiles/R2901623_096.nc ... Provor, Seabird conductivity sensor
[98 rows x 11 columns]
OceanOPSDeployments can also take an index box definition as argument in order to restrict the deployment plan selection to a specific region or period:
deployment = OceanOPSDeployments([-90, 0, 0, 90])
# deployment = OceanOPSDeployments([-20, 0, 42, 51, '2020-01', '2021-01'])
# deployment = OceanOPSDeployments([-180, 180, -90, 90, '2020-01', None])
Note that if the starting date is not provided, it will be set automatically to the current date.
Last, OceanOPSDeployments comes with a plotting method:
fig, ax = deployment.plot_status()
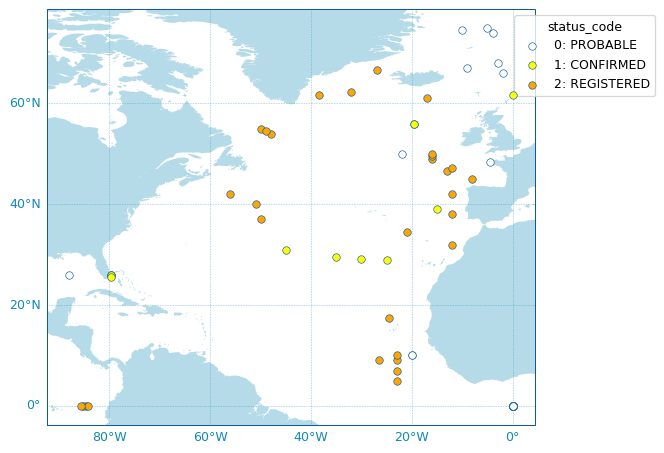
Note
The list of possible deployment status name/code is given by:
OceanOPSDeployments().status_code
Status |
Id |
Description |
|---|---|---|
PROBABLE |
0 |
Starting status for some platforms, when there is only a few metadata available, like rough deployment location and date. The platform may be deployed |
CONFIRMED |
1 |
Automatically set when a ship is attached to the deployment information. The platform is ready to be deployed, deployment is planned |
REGISTERED |
2 |
Starting status for most of the networks, when deployment planning is not done. The deployment is certain, and a notification has been sent via the OceanOPS system |
OPERATIONAL |
6 |
Automatically set when the platform is emitting a pulse and observations are distributed within a certain time interval |
INACTIVE |
4 |
The platform is not emitting a pulse since a certain time |
CLOSED |
5 |
The platform is not emitting a pulse since a long time, it is considered as dead |