What’s New#





Coming up next (unreleased)#
Features and front-end API#
Full Argo vocabulary support for reference tables (
ArgoReferenceTable), values (ArgoReferenceValue) and mappings (ArgoReferenceMapping) (#575) by G. Maze.
Internals#
Documentation#
v1.4.0 (5 Jan. 2026)#
Features and front-end API#
Predict nutrients and carbonates in the global ocean with their uncertainties with the two new classes
Dataset.argo.canyon_bandDataset.argo.content. The first class allows users to make predictions of the water-column nutrient concentrations (NO3, PO4, SiOH4) and carbonate system variables (AT, DIC, pHT, pCO2) using the CANYON-B model (see doc.) while the second class provides improved predictions of carbonate system variables using the CONTENT (see doc.) model. (#535 and #542) by F. Ricour. It goes as simply as:
from argopy import DataFetcher
ArgoSet = DataFetcher(ds='bgc', params='DOXY', measured='DOXY').float(1902605)
ds = ArgoSet.to_xarray()
ds.argo.canyon_b.predict()
# or
ds.argo.content.predict()
New extensions
ArgoFloat.configandArgoFloat.launchconfigto easily access one float configuration parameter values. (#558) by G. Maze.New queries to search institution-related entries in an
ArgoIndex:ArgoIndex.query.institution_code(),ArgoIndex.query.institution_name()andArgoIndex.query.dac(), #527. (#528) by G. Maze.
Internals#
Add llms.txt generation, a file to provide information to help LLMs use Argopy documentation. See https://llmstxt.org for more.
Fix bug whereby an error was raise when interpolating on SDL a dataset loaded from an
ArgoFloatinstance. (#564) by G. Maze.Fix bug whereby a scatter_plot would fail for a parameter with only N_PROF as dimensions. (#564) by G. Maze.
Fix bug whereby missing values in <PARAM>_QC variables of xarray dataset were casted as 0 instead of 9. (@d7bbc23) by G. Maze.
Fix upstream compatibility and imposes xarray >=2025.7 and <=2025.9.0. (#539).
Removed python 3.10 environments from ci/env_managers CLI utility. (#557) by G. Maze.
Breaking changes#
In the
pandas.DataFrameoutput of theArgoIndex.to_dataframe()method (#528) by G. Maze:column institution_code is renamed institution, to preserve the original Argo index file column name,
column institution is renamed by institution_name, to make explicit this is an Argopy addition.
Deprecation warning for
plot.scatter_plot()argumentsthis_x,this_yandparamthat are replaced byx,yandparam. (#557) by G. Maze.Internal refactoring, former argopy.utils.transform now argopy.utils.transformers, former argopy.utils.compute now argopy.utils.computers. (#557) by G. Maze.
Energy#
v1.3.1 (22 Oct. 2025)#
Features and front-end API#
New colormap in
ArgoColorsfor whole profile QC flags. See the new documentation section on Argo colors for more. (#515) by G. Maze.Improved
ArgoFloat.plotmethods: now auto-select colormap, colorbar and legend settings depending on the parameter to plot. Check the documentation at: Plotting features. (#515) by G. Maze.
Internals#
For mainteners, add a public CLI script
cli/update_json_assetsto update static assets. (#540) by G. Maze.Update list of Reference tables with R14 on “Argo technical parameter names” and R31 on “Argo float ending cause”. The
ArgoNVSReferenceTablesinternal list of valid reference tables is now taken from a static asset file generated withcli/update_json_assetson each new release. (#540) by G. Maze.Fix bug whereby no static asset subfolders were included in the pypi and conda distribution, thus making the
Dataset.argo.canyon_medpredictor to raise an error when predictions were triggered #530. (#531) by G. Maze.Fix bug whereby profiles with Real time only data mode data failed to pass
Dataset.argo.datamode.merge()without raising an error, #517, #519. (#518) by G. Maze.Updated User-Agent header field for HTTP requests. The default aiottp header field User-Agent is now complemented with Argopy information in order to ease server side log analysis. The User-Agent is now somethink like:
"User-Agent": Python/3.11 aiohttp/3.12.14 Argopy/1.3.0 (+https://github.com/euroargodev/argopy), #533. (#534) by G. Maze.New post method for the
stores.httpstoreallowing for HTTP POST methods to web-API, by G. Maze.Fix upstream compatibility whereby xarray >= 2025.8 deprecation cycle for changing default keyword arguments in
xarray.merge()andxarray.concat()would make Argopy to fail with internal data processing, #521. (#504) by G. Maze.
Energy#
v1.3.0 (22 Aug. 2025)#
Added in version v1.3.0: This new argopy version requires Python 3.11 !
Features and front-end API#
ArgoIndexplotting features: you can now use the newArgoIndex.plotaccessor to call on visualizations tool for trajectories or parameters bar plots. See all details on the documentation section about data visualization From ArgoIndex instance. (#504) by G. Maze.ArgoFloatplotting features: you can now use the newArgoFloat.plotaccessor to call on visualizations tool for trajectories and parameters. See all details on the documentation section about data visualization From ArgoFloat instance. (#501) by G. Maze.
Internals#
Fix bug whereby depending on the new longitude convention option value, some floats trajectory would not show up on a map correctly. (#504) by G. Maze.
Refactoring of
ArgoIndexandArgoFloatto follow the same specs/facade/implementations/extensions design. (#503)by G. Maze.Fix bug whereby the
ArgoIndexcould not select profiles through the dateline #494. (#495) by G. Maze. Modified by #506.Fix bug whereby a
gdacfscould not return one path info under Windows platform. #499. (#451) by G. Maze.Identified incompatible versions of xarray. Because of this issue argopy is not compatible with xarray versions from 2024.3.0 to 2025.6.1, included. (#451) by G. Maze.
Breaking changes#
New argopy option longitude_convention and improved box region validation with
argopy.utils.is_box()andargopy.utils.is_indexbox()may lead to unexpected breaking changes. You may need to change the longitude convention from the default ‘180’ to ‘360’ to fix your code. (#506) by G. Maze.argopy.utils.wmo2box()now return domain with longitude values following the new argopy option longitude_convention. (#506) by G. Maze.argopy.plot.scatter_mapnow return 3 values for the figure, axis and handles, instead of 2 values (#501) by G. Maze.Drop support for Python 3.10
Energy#
v1.2.0 (9 June 2025)#
Features and front-end API#
Optical modeling diagnostics for BGC data. We introduce a preliminary implementation of standard diagnostics from optical modeling. These are available through the new
Dataset.argo.opticextension. All details are in the dedicated Optical modeling documentation page and on the API reference. (#463) by G. Maze.Optimized diagnostic per profile. If you want to execute your own diagnostic method on a collection of Argo profiles, argopy now provides an efficient method to do so:
Dataset.argo.reduce_profile(). Typical use case would include computation of the mixed layer depth or euphotic layer depth. All details are in the dedicated Per profile custom diagnostic documentation page and on the API reference of the method. (#463) by G. Maze.
ArgoIndexnow support composition of several search criteria. Thanks to a re-design of the Argo index search engine, it is now easy to use multiple search criteria to query an Argo files index. Checkout the dedicated Argo Index store documentation page. (#470) by G. Maze.Fetch Argo data as
netCDF4.Dataset. For the sake of compatibility with legacy codes and to encourage argopy adoption for all loading/reading operations, we now support data output as a netCDF4 Dataset object. This new feature is available at high level with theDataFetcherand lower-level with theArgoFloatandgdacfsclasses. (#484) by G. Maze.
Internals#
Open netcdf files lazily from ftp server. Adding to s3 and http, we now support laziness with ftp using kerchunk. Checkout the dedicated Lazy dataset access section of the documentation. (#460) by G. Maze.
Energy#
v1.1.0 (18 March 2025)#
Added in version v1.1.0: Most new features in this version can be considered advanced tools, since they require a more intimate knowledge of the Argo dataset. Therefore, we re-organised and completed the argopy documentation to give them more visibility.
Features and front-end API#
New
ArgoFloatstore for Argo netcdf file load/read operations. Whatever the Argo netcdf file location, local or remote, you can now delegate to argopy the burden of transfer protocol and GDAC paths handling. This store is primarily intended to be used by third party libraries or in workflow by operators and experts. Checkout the dedicated Argo Float store documentation page. (#429) by G. Maze.New generic file system for any GDAC host
gdacfs. This class allows to easily creates a file system for any of the possible GDAC paths. This class returns one of the argopy file systems (file, http, ftp or s3) with a prefixed directory, so that you don’t have to include the GDAC path in resources to open. The goal of this class is to separate the data source from the data processing in your workflow. Checkout the dedicated Store for GDAC files documentation page. (#385, #440) by G. Maze.Experimental new data source: AWS S3 netcdf files. This support is primarily made available for benchmarking as part of the ADMT working group on Argo cloud format activities. (#385) by G. Maze. In order to use the experimental S3 GDAC, you can point the
gdacoption to the appropriate s3 bucket:
with argopy.set_options(gdac='s3://argo-gdac-sandbox/pub'):
ds = DataFetcher(src='gdac').float(6903091).to_xarray()
ArgoIndexsupport meta index file. We now offer support for the index of meta dataset files. This support brings two new methods to search the profiler type index column: one method based on the profiler type number and another method based on a string match in the profile type label, as described in the Argo Reference table 8. Checkout the dedicated Argo Index store documentation page.
from argopy import ArgoIndex
idx = ArgoIndex(index_file='meta').load()
idx.search_profiler_type([838, 878])
idx.search_profiler_label('ARVOR')
New class
utils.GreenCodingto compute argopy carbon footprint. This class makes it easy to use the Green-Coding Solutions API to retrieve argopy energy consumption data. This class is primarily used for reporting. Checkout the dedicated Energy documentation page. (#437) by G. Maze.
from argopy.utils import GreenCoding
GreenCoding().measurements(branch='master', start_date='2025-01-01')
GreenCoding().total_measurements(branches=['385/merge', '437/merge'])
GreenCoding().footprint_since_last_release()
GreenCoding().footprint_for_release('v1.0.0')
GreenCoding().footprint_all_releases()
GreenCoding().footprint_baseline()
Internals#
argopy file systems refactoring. Long due internal refactoring of File systems. The submodule now adopt a more readable specification vs implementation design. This should not break or change high level APIs.(#425) by G. Maze.
Support Argo dataset export to zarr. Provide preliminary support to export Argo datasets to zarr files (local or remote). (#423) by G. Maze.
from argopy import DataFetcher
ds = DataFetcher(src='gdac').float(6903091).to_xarray()
# then:
ds.argo.to_zarr("6903091_prof.zarr")
# or:
ds.argo.to_zarr("s3://argopy/sample-data/6903091_prof.zarr")
Open netcdf files lazily. We provide an experimental low-level support for opening a netcdf Argo dataset lazily using kerchunk. Checkout the dedicated Lazy dataset access section of the documentation. (#385) by G. Maze.
Fix bug raised when the Argo reference table 8 return by the NVS server has a missing altLabel. ID of platform types are now extracted from the NVS url ID property. #420, (#421) by G. Maze.
When argopy is sending a http request to a data server, add a custom http header
Argopy-Versionto ease server log analysis. (#407) by G. Maze.New
ArgoIndex.copy()method (#418) by G. Maze. This copy allows for a:deep copy, i.e. a new instance with same parameters (e.g.
index_file) and cleared search,shallow copy, i.e. a new instance with same parameters and search results if any.
Fix bug raising an error for
STATION_PARAMETERSwith a blank entry, withbgcdataset andgdacdata source (well spotted K. Balem). (#418) by G. Maze.Fix bug raising an error when exporting a dataset to netcdf after erddap fetch, #412. (#413) by G. Maze.
The
Dataset.argo.canyon_medpredictor raises errors if not dealing with a collection of Argo points. (#450) by G. Maze.
Make the
Dataset.argoaccessor and its extensions able to work with dataset from aDataFetcherand from aArgoFloat. This was necessary because the time variable does not have the same name in these dataset (TIMEvsJULD). But this point should be addressed later. (#450) by G. Maze.
Energy#
v1.0.0 (16 Oct. 2024)#
Added in version v1.0.0: The team proudly assumes that argopy is all grown up !
This version comes with improved performances and support for the BGC-Argo dataset. But since this is a major, we also introduces breaking changes and significant internal refactoring possibly with un-expected side effects ! So don’t hesitate to report issues on the source code repository.
Features and front-end API#
Support for AWS S3 data files. This support is experimental and is primarily made available for benchmarking as part of the ADMT working group on Argo cloud format activities.
- Improved support for BGC
argopy now support `standard` and `research` user modes with the bgc dataset. These new user modes follows the last available ADMT recommendations to bring users a finely tuned set of BGC parameters. Details of the BGC data processing chain for each user modes can be found in the Definitions section.
Predict nutrients and carbonates in the Mediterranean Sea with the new BGC method
Dataset.argo.canyon_med. The new method allows to make predictions of the water-Column nutrient concentrations and carbonate system variables in the Mediterranean Sea with the CANYON-MED model. This model can be used to predict PO4, NO3, DIC, SiOH4, AT and pHT. (#364) by G. Maze.
from argopy import DataFetcher ArgoSet = DataFetcher(ds='bgc', mode='standard', params='DOXY', measured='DOXY').float(1902605) ds = ArgoSet.to_xarray() ds.argo.canyon_med.predict() ds.argo.canyon_med.predict('PO4')
More BGC expert features with support for the auxiliary index file with
argopy.ArgoIndex. Simply use the keyword aux. (#356) by G. Maze.
from argopy import ArgoIndex ArgoIndex(index_file="aux").load()
More scalable data fetching using multi-processing or a Dask Cluster.
It is now possible to use multi-processing with all data fetchers and even possibly a Dask client object. This is set with the parallel option. In doing so, the Argo data pre-processing steps (download and conformation to internal conventions) will be distributed to all available resources, significantly improving performances for fetching large selection of Argo data. (#392) by G. Maze.
Check the documentation on Parallelization methods for all the details.
from dask.distributed import Client
client = Client(processes=True)
from argopy import DataFetcher
DataFetcher(parallel=client, src='argovis').region([-75, -65, 25, 40, 0, 250, '2020-01-01', '2021-01-01']).to_xarray()
Xarray argo accessor extensions mechanism.
This should allows users to easily develop their own Argo dataset methods. This is possible thanks to a new class decorator argopy.extensions.register_argo_accessor that allows to register a class as a property to the Dataset.argo accessor. (#364) by G. Maze.
Example:
@register_argo_accessor('floats')
class WorkWithWMO(ArgoAccessorExtension):
"""Example of a new Argo dataset feature"""
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self._uid = argopy.utils.to_list(np.unique(self._obj["PLATFORM_NUMBER"].values))
@property
def wmo(self):
return self._uid
@property
def N(self):
return len(self.wmo)
This makes syntax like this possible:
ds.argo.floats.N
ds.argo.floats.wmo
Breaking changes#
- In the
Dataset.argoaccessor (#356) by G. Maze: the
Dataset.argo.filter_data_mode()has been deprecated and replaced byDataset.argo.datamode.merge()method. To actually implement a real filter of data points on data mode values, i.e. to keep points with specific data mode values, use theDataset.argo.datamode.filter()method.
- In the
The option name “ftp” is now renamed “gdac” (#389) by G. Maze.
The option name “dataset” is now renamed “ds” (#389) by G. Maze.
It is highly probable that more changes in this major v1.0.0 lead to breaking changes not listed here. Don’t hesitate to report them on the repository issue section.
Energy#
v0.1.17 (20 Sep. 2024)#
This is the last minor version release
We’re very happy to announce that this v0.1.17 is the last of the minor version releases. Its main role is to introduce deprecation warnings before things break in the major version release.
Comping up soon by the end of October the first major argopy release: v1.0.0
Important
List of deprecations before the upcoming major release v1.0.0. (#389) by G. Maze.
Change of signature and action with xarray Argo accessor
Dataset.argo.filter_data_mode()
Refactor option “dataset” into “ds”, see
argopy.set_optionsRefactor option “ftp” into “gdac”, see
argopy.set_options
Internals#
Energy#
v0.1.16 (27 Aug. 2024)#
Features and front-end API#
Support for AWS S3 index files. This support is experimental and is primarily made available for benchmarking as part of the ADMT working group on Argo cloud format activities. The ADMT working group discussion items are listed here. Both CORE and BGC index files are supported. The new
ArgoIndexnot only support access to the AWS S3 index files but also implement improved performances for search methods on WMO and cycle numbers, usingboto3.client.select_object_contentSQL queries. Indeed, thehttpsandftpdefault GDAC server index files are downloaded and loaded in memory before being searched. But withs3, index files can directly be queried on the server using SQL syntax; the full index is not necessarily downloaded. (#326) by G. Maze
from argopy import ArgoIndex
idx = ArgoIndex(host='s3') # you can also use 'aws' as a keyword for 's3://argo-gdac-sandbox/pub/idx'
# Optimised perf with boto3.client.select_object_content queries for WMO and cycle numbers:
idx.search_wmo(6903091)
idx.search_cyc(12)
idx.search_wmo_cyc(6903091, 23)
# Other search methods will trigger download of the index file, eg:
idx.search_tim([-60, -55, 40., 45., '2007-08-01', '2007-09-01'])
argovis data source now support the new API server. This upgrade comes with a new option to define the optional API KEY to use. You can get a free key here. (#371) by Bill Katie-Anne Mills.
argopy is concerned about its environmental impact and we’d like to understand and optimize the carbon emissions of our digital activities. Starting June 1st 2024, we use Green Coding tools to assess energy consumption and CO2eq emissions from our activities on Github infrastructure. All results and data are available on the new dedicated web page: Carbon emissions. (#354) by G. Maze.
Internals#
Drop support for Python 3.8, add support for Python 3.10. (#379) by G. Maze
Update
argopy.ArgoNVSReferenceTablesto handle new NVS server output format. (#378) by G. Maze.Update Ifremer erddap server information. The Argo reference for DMQC (returned by the
DataFetcherfetcher withds='ref'argument ) and Argo CTD-reference for DQMC (returned by theCTDRefDataFetcherfetcher) now indicate the dataset version used. (#344) by G. Maze.Pin upper bound on xarray < 2024.3 to fix failing upstream tests because of
AttributeError: 'ScipyArrayWrapper' object has no attribute 'oindex', reported here. (#326) by G. MazeFix
argopy.ArgoDocsthat was not working with new Archimer webpage design, #351. (#352) by G. Maze.Update
argopy.ArgoDocswith last BGC cookbooks on pH. (#321) by G. Maze.
Breaking changes#
Energy#
v0.1.15 (12 Dec. 2023)#
Internals#
Fix bug whereby user name could not be retrieved using
getpass.getuser(). This closes #310 and allows argopy to be integrated into the EU Galaxy tools for ecology. (#311) by G. Maze.
v0.1.14 (29 Sep. 2023)#
Added in version v0.1.14: This new release brings to pip and conda default install of argopy all new features introduced in the release candidate v0.1.14rc2 and v0.1.14rc1. For simplicity we merged all novelties to this v0.1.14 changelog.
Features and front-end API#
argopy now support BGC dataset in `expert` user mode for the `erddap` data source. The BGC-Argo content of synthetic multi-profile files is now available from the Ifremer erddap. Like for the core dataset, you can fetch data for a region, float(s) or profile(s). One novelty with regard to core, is that you can restrict data fetching to some parameters and furthermore impose no-NaNs on some of these parameters. Check out the new documentation page for Dataset. (#278) by G. Maze
import argopy
from argopy import DataFetcher
argopy.set_options(src='erddap', mode='expert')
DataFetcher(ds='bgc') # All variables found in the access point will be returned
DataFetcher(ds='bgc', params='all') # Default: All variables found in the access point will be returned
DataFetcher(ds='bgc', params='DOXY') # Only the DOXY variable will be returned
DataFetcher(ds='bgc', params=['DOXY', 'BBP700']) # Only DOXY and BBP700 will be returned
DataFetcher(ds='bgc', measured=None) # Default: all params are allowed to have NaNs
DataFetcher(ds='bgc', measured='all') # All params found in the access point cannot be NaNs
DataFetcher(ds='bgc', measured='DOXY') # Only DOXY cannot be NaNs
DataFetcher(ds='bgc', measured=['DOXY', 'BBP700']) # Only DOXY and BBP700 cannot be NaNs
DataFetcher(ds='bgc', params='all', measured=None) # Return the largest possible dataset
DataFetcher(ds='bgc', params='all', measured='all') # Return the smallest possible dataset
DataFetcher(ds='bgc', params='all', measured=['DOXY', 'BBP700']) # Return all possible params for points where DOXY and BBP700 are not NaN
New methods in the ArgoIndex for BGC. The
ArgoIndexhas now full support for the BGC profile index files, both bio and synthetic index. In particular it is possible to search for profiles with specific data modes on parameters. (#278) by G. Maze
from argopy import ArgoIndex
idx = ArgoIndex(index_file="bgc-b") # Use keywords instead of exact file names: `core`, `bgc-b`, `bgc-s`
idx.search_params(['C1PHASE_DOXY', 'DOWNWELLING_PAR']) # Search for profiles with parameters
idx.search_parameter_data_mode({'TEMP': 'D'}) # Search for profiles with specific data modes
idx.search_parameter_data_mode({'BBP700': 'D'})
idx.search_parameter_data_mode({'DOXY': ['R', 'A']})
idx.search_parameter_data_mode({'DOXY': 'D', 'CDOM': 'D'}, logical='or')
New xarray argo accessor features. Easily retrieve an Argo sample index and domain extent with the
indexanddomainproperties. Get a list with all possible (PLATFORM_NUMBER, CYCLE_NUMBER) with thelist_WMO_CYCmethod. (#278) by G. MazeNew search methods for Argo reference tables. It is now possible to search for a string in tables title and/or description using the
related.ArgoNVSReferenceTables.search()method.
from argopy import ArgoNVSReferenceTables
id_list = ArgoNVSReferenceTables().search('sensor')
Updated documentation. In order to better introduce new features, we updated the documentation structure and content.
argopy cheatsheet ! Get most of the argopy API in a 2 pages pdf !

Our internal Argo index store is promoted as a frontend feature. The
IndexFetcheris a user-friendly fetcher built on top of our internal Argo index file store. But if you are familiar with Argo index files and/or cares about performances, you may be interested in using directly the Argo index store. We thus decided to promote this internal feature as a frontend classArgoIndex. See Argo Index store. (#270) by G. MazeEasy access to all Argo manuals from the ADMT. More than 20 pdf manuals have been produced by the Argo Data Management Team. Using the new
ArgoDocsclass, it’s now easier to navigate this great database for Argo experts. All details in ADMT Documentation. (#268) by G. Maze
from argopy import ArgoDocs
ArgoDocs().list
ArgoDocs(35385)
ArgoDocs(35385).ris
ArgoDocs(35385).abstract
ArgoDocs(35385).show()
ArgoDocs(35385).open_pdf()
ArgoDocs(35385).open_pdf(page=12)
ArgoDocs().search("CDOM")
New ‘research’ user mode. This new feature implements automatic filtering of Argo data following international recommendations for research/climate studies. With this user mode, only Delayed Mode with good QC data are returned. Check out the Definitions section for all the details. (#265) by G. Maze
argopy now provides a specific xarray engine to properly read Argo netcdf files. Using
engine='argo'inxarray.open_dataset(), all variables will properly be casted, i.e. returned with their expected data types, which is not the case otherwise. This works with ALL Argo netcdf file types (as listed in the Reference table R01). Some details in here:argopy.xarray.ArgoEngine(#208) by G. Maze
import xarray as xr
ds = xr.open_dataset("dac/aoml/1901393/1901393_prof.nc", engine='argo')
argopy now can provide authenticated access to the Argo CTD reference database for DMQC. Using user/password new argopy options, it is possible to fetch the Argo CTD reference database, with the
CTDRefDataFetcherclass. (#256) by G. Maze
from argopy import CTDRefDataFetcher
with argopy.set_options(user="john_doe", password="***"):
f = CTDRefDataFetcher(box=[15, 30, -70, -60, 0, 5000.0])
ds = f.to_xarray()
Warning
argopy is ready but the Argo CTD reference database for DMQC is not fully published on the Ifremer ERDDAP yet. This new feature will thus be fully operational soon, and while it’s not, argopy should raise an ErddapHTTPNotFound error when using the new fetcher.
New option to control the expiration time of cache file:
cache_expiration.
Internals#
Utilities refactoring. All classes and functions have been refactored to more appropriate locations like
argopy.utilsorargopy.related. A deprecation warning message should be displayed every time utilities are being used from the deprecated locations. (#290) by G. MazeFix bugs due to fsspec new internal cache handling and Windows specifics. (#293) by G. Maze
New utility class
utils.MonitoredThreadPoolExecutorto handle parallelization with a multi-threading Pool that provide a notebook or terminal computation progress dashboard. This class is used by the httpstore open_mfdataset method for erddap requests.New utilities to handle a collection of datasets:
utils.drop_variables_not_in_all_datasets()will drop variables that are not in all datasets (the lowest common denominator) andutils.fill_variables_not_in_all_datasets()will add empty variables to dataset so that all the collection have the same data_vars and coords. These functions are used by stores to concat/merge a collection of datasets (chunks).related.load_dict()now relies onArgoNVSReferenceTablesinstead of static pickle files.argopy.ArgoColorscolormap for Argo Data-Mode has now a fourth value to account for a white space FillValue.New quick and dirty plot method
plot.scatter_plot()Refactor pickle files in argopy/assets as json files in argopy/static/assets
Refactor list of variables by data types used in
related.cast_Argo_variable_type()into assets json files in argopy/static/assetsChange of behaviour: when setting the cachedir option, path it’s not tested for existence but for being writable, and is created if doesn’t exists (but seems to break CI upstream in Windows)
And misc. bug and warning fixes all over the code.
Update new argovis dashboard links for floats and profiles. (#271) by G. Maze
Index store can now export search results to standard Argo index file format. See all details in Argo Index store. (#260) by G. Maze
from argopy import ArgoIndex as indexstore
# or:
# from argopy.stores import indexstore_pd as indexstore
# or:
# from argopy.stores import indexstore_pa as indexstore
idx = indexstore().search_wmo(3902131) # Perform any search
idx.to_indexfile('short_index.txt') # export search results as standard Argo index csv file
Index store can now load/search the Argo Bio and Synthetic profile index files. Simply gives the name of the Bio or Synthetic Profile index file and retrieve the full index. This store also comes with a new search criteria for BGC: by parameters. See all details in Argo Index store. (#261) by G. Maze
from argopy import ArgoIndex as indexstore
# or:
# from argopy.stores import indexstore_pd as indexstore
# or:
# from argopy.stores import indexstore_pa as indexstore
idx = indexstore(index_file="argo_bio-profile_index.txt").load()
idx.search_params(['C1PHASE_DOXY', 'DOWNWELLING_PAR'])
Breaking changes#
v0.1.14rc2 (27 Jul. 2023)#
Features and front-end API#
argopy now support BGC dataset in `expert` user mode for the `erddap` data source. The BGC-Argo content of synthetic multi-profile files is now available from the Ifremer erddap. Like for the core dataset, you can fetch data for a region, float(s) or profile(s). One novelty with regard to core, is that you can restrict data fetching to some parameters and furthermore impose no-NaNs on some of these parameters. Check out the new documentation page for Dataset. (#278) by G. Maze
import argopy
from argopy import DataFetcher
argopy.set_options(src='erddap', mode='expert')
DataFetcher(ds='bgc') # All variables found in the access point will be returned
DataFetcher(ds='bgc', params='all') # Default: All variables found in the access point will be returned
DataFetcher(ds='bgc', params='DOXY') # Only the DOXY variable will be returned
DataFetcher(ds='bgc', params=['DOXY', 'BBP700']) # Only DOXY and BBP700 will be returned
DataFetcher(ds='bgc', measured=None) # Default: all params are allowed to have NaNs
DataFetcher(ds='bgc', measured='all') # All params found in the access point cannot be NaNs
DataFetcher(ds='bgc', measured='DOXY') # Only DOXY cannot be NaNs
DataFetcher(ds='bgc', measured=['DOXY', 'BBP700']) # Only DOXY and BBP700 cannot be NaNs
DataFetcher(ds='bgc', params='all', measured=None) # Return the largest possible dataset
DataFetcher(ds='bgc', params='all', measured='all') # Return the smallest possible dataset
DataFetcher(ds='bgc', params='all', measured=['DOXY', 'BBP700']) # Return all possible params for points where DOXY and BBP700 are not NaN
New methods in the ArgoIndex for BGC. The
ArgoIndexhas now full support for the BGC profile index files, both bio and synthetic index. In particular it is possible to search for profiles with specific data modes on parameters. (#278) by G. Maze
from argopy import ArgoIndex
idx = ArgoIndex(index_file="bgc-b") # Use keywords instead of exact file names: `core`, `bgc-b`, `bgc-s`
idx.search_params(['C1PHASE_DOXY', 'DOWNWELLING_PAR']) # Search for profiles with parameters
idx.search_parameter_data_mode({'TEMP': 'D'}) # Search for profiles with specific data modes
idx.search_parameter_data_mode({'BBP700': 'D'})
idx.search_parameter_data_mode({'DOXY': ['R', 'A']})
idx.search_parameter_data_mode({'DOXY': 'D', 'CDOM': 'D'}, logical='or')
New xarray argo accessor features. Easily retrieve an Argo sample index and domain extent with the
indexanddomainproperties. Get a list with all possible (PLATFORM_NUMBER, CYCLE_NUMBER) with thelist_WMO_CYCmethod. (#278) by G. MazeNew search methods for Argo reference tables. It is now possible to search for a string in tables title and/or description using the
related.ArgoNVSReferenceTables.search()method.
from argopy import ArgoNVSReferenceTables
id_list = ArgoNVSReferenceTables().search('sensor')
Updated documentation. In order to better introduce new features, we updated the documentation structure and content.
Internals#
New utility class
utils.MonitoredThreadPoolExecutorto handle parallelization with a multi-threading Pool that provide a notebook or terminal computation progress dashboard. This class is used by the httpstore open_mfdataset method for erddap requests.New utilities to handle a collection of datasets:
utils.drop_variables_not_in_all_datasets()will drop variables that are not in all datasets (the lowest common denominator) andutils.fill_variables_not_in_all_datasets()will add empty variables to dataset so that all the collection have the same data_vars and coords. These functions are used by stores to concat/merge a collection of datasets (chunks).related.load_dict()now relies onArgoNVSReferenceTablesinstead of static pickle files.argopy.ArgoColorscolormap for Argo Data-Mode has now a fourth value to account for a white space FillValue.New quick and dirty plot method
plot.scatter_plot()Refactor pickle files in argopy/assets as json files in argopy/static/assets
Refactor list of variables by data types used in
related.cast_Argo_variable_type()into assets json files in argopy/static/assetsChange of behaviour: when setting the cachedir option, path it’s not tested for existence but for being writable, and is created if doesn’t exists (but seems to break CI upstream in Windows)
And misc. bug and warning fixes all over the code.
Breaking changes#
Some documentation pages may have moved to new urls.
v0.1.14rc1 (31 May 2023)#
Features and front-end API#
argopy cheatsheet ! Get most of the argopy API in a 2 pages pdf !
Our internal Argo index store is promoted as a frontend feature. The
IndexFetcheris a user-friendly fetcher built on top of our internal Argo index file store. But if you are familiar with Argo index files and/or cares about performances, you may be interested in using directly the Argo index store. We thus decided to promote this internal feature as a frontend classArgoIndex. See Argo Index store. (#270) by G. MazeEasy access to all Argo manuals from the ADMT. More than 20 pdf manuals have been produced by the Argo Data Management Team. Using the new
ArgoDocsclass, it’s now easier to navigate this great database for Argo experts. All details in ADMT Documentation. (#268) by G. Maze
from argopy import ArgoDocs
ArgoDocs().list
ArgoDocs(35385)
ArgoDocs(35385).ris
ArgoDocs(35385).abstract
ArgoDocs(35385).show()
ArgoDocs(35385).open_pdf()
ArgoDocs(35385).open_pdf(page=12)
ArgoDocs().search("CDOM")
New ‘research’ user mode. This new feature implements automatic filtering of Argo data following international recommendations for research/climate studies. With this user mode, only Delayed Mode with good QC data are returned. Check out the Definitions section for all the details. (#265) by G. Maze
argopy now provides a specific xarray engine to properly read Argo netcdf files. Using
engine='argo'inxarray.open_dataset(), all variables will properly be casted, i.e. returned with their expected data types, which is not the case otherwise. This works with ALL Argo netcdf file types (as listed in the Reference table R01). Some details in here:argopy.xarray.ArgoEngine(#208) by G. Maze
import xarray as xr
ds = xr.open_dataset("dac/aoml/1901393/1901393_prof.nc", engine='argo')
argopy now can provide authenticated access to the Argo CTD reference database for DMQC. Using user/password new argopy options, it is possible to fetch the Argo CTD reference database, with the
CTDRefDataFetcherclass. (#256) by G. Maze
from argopy import CTDRefDataFetcher
with argopy.set_options(user="john_doe", password="***"):
f = CTDRefDataFetcher(box=[15, 30, -70, -60, 0, 5000.0])
ds = f.to_xarray()
Warning
argopy is ready but the Argo CTD reference database for DMQC is not fully published on the Ifremer ERDDAP yet. This new feature will thus be fully operational soon, and while it’s not, argopy should raise an ErddapHTTPNotFound error when using the new fetcher.
New option to control the expiration time of cache file:
cache_expiration.
Internals#
Update new argovis dashboard links for floats and profiles. (#271) by G. Maze
Index store can now export search results to standard Argo index file format. See all details in Argo Index store. (#260) by G. Maze
from argopy import ArgoIndex as indexstore
# or:
# from argopy.stores import indexstore_pd as indexstore
# or:
# from argopy.stores import indexstore_pa as indexstore
idx = indexstore().search_wmo(3902131) # Perform any search
idx.to_indexfile('short_index.txt') # export search results as standard Argo index csv file
Index store can now load/search the Argo Bio and Synthetic profile index files. Simply gives the name of the Bio or Synthetic Profile index file and retrieve the full index. This store also comes with a new search criteria for BGC: by parameters. See all details in Argo Index store. (#261) by G. Maze
from argopy import ArgoIndex as indexstore
# or:
# from argopy.stores import indexstore_pd as indexstore
# or:
# from argopy.stores import indexstore_pa as indexstore
idx = indexstore(index_file="argo_bio-profile_index.txt").load()
idx.search_params(['C1PHASE_DOXY', 'DOWNWELLING_PAR'])
Breaking changes#
v0.1.13 (28 Mar. 2023)#
Features and front-end API#
New utility class to retrieve the Argo deployment plan from the Ocean-OPS api. This is the utility class
OceanOPSDeployments. See the new documentation section on Deployment Plan for more. (#244) by G. Maze
from argopy import OceanOPSDeployments
deployment = OceanOPSDeployments()
deployment = OceanOPSDeployments([-90,0,0,90])
deployment = OceanOPSDeployments([-90,0,0,90], deployed_only=True) # Remove planification
df = deployment.to_dataframe()
deployment.status_code
fig, ax = deployment.plot_status()
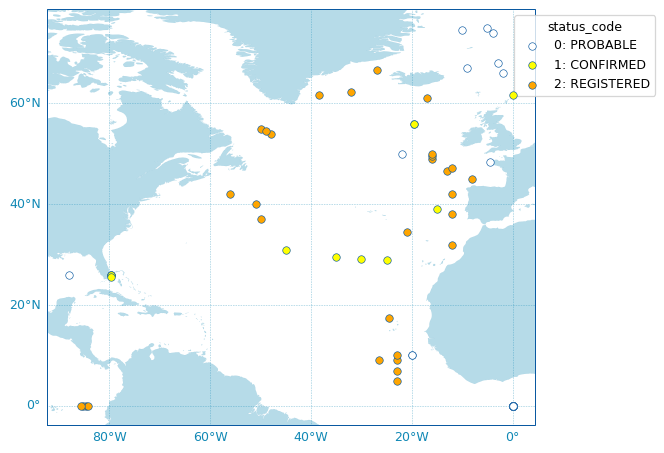
New scatter map utility for easy Argo-related variables plotting. The new
argopy.plot.scatter_map()utility function is dedicated to making maps with Argo profiles positions coloured according to specific variables: a scatter map. Profiles colouring is finely tuned for some variables: QC flags, Data Mode and Deployment Status. By default, floats trajectories are always shown, but this can be changed. See the new documentation section on Scatter Maps for more. (#245) by G. Maze
from argopy.plot import scatter_map
fig, ax = scatter_map(ds_or_df,
x='LONGITUDE', y='LATITUDE', hue='PSAL_QC',
traj_axis='PLATFORM_NUMBER')
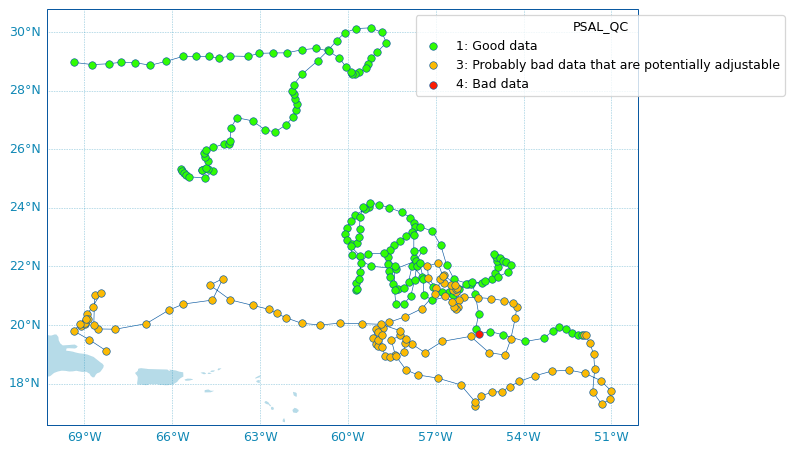
New Argo colors utility to manage segmented colormaps and pre-defined Argo colors set. The new
argopy.plot.ArgoColorsutility class aims to easily provide colors for Argo-related variables plot. See the new documentation section on Argo colors for more (#245) by G. Maze
from argopy.plot import ArgoColors
ArgoColors().list_valid_known_colormaps
ArgoColors().known_colormaps.keys()
ArgoColors('data_mode')
ArgoColors('data_mode').cmap
ArgoColors('data_mode').definition
ArgoColors('Set2').cmap
ArgoColors('Spectral', N=25).cmap
Internals#
Because of the new
argopy.plot.ArgoColors, the argopy.plot.discrete_coloring utility is deprecated in 0.1.13. Calling it will raise an error after argopy 0.1.14. (#245) by G. MazeNew method to check status of web API: now allows for a keyword check rather than a simple url ping. This comes with 2 new utilities functions
utilities.urlhaskeyword()andutilities.isalive(). (#247) by G. Maze.Removed dependency to Scikit-learn LabelEncoder (#239) by G. Maze
Breaking changes#
Data source
localftpis deprecated and removed from argopy. It’s been replaced by thegdacdata source with the appropriateftpoption. See Data sources. (#240) by G. Mazeargopy.utilities.ArgoNVSReferenceTablesmethodsall_tblandall_tbl_nameare now properties, not methods.
v0.1.12 (16 May 2022)#
Internals#
Update
erddapserver from https://www.ifremer.fr/erddap to https://erddap.ifremer.fr/erddap. (@af5692f) by G. Maze
v0.1.11 (13 Apr. 2022)#
Features and front-end API#
New data source ``gdac`` to retrieve data from a GDAC compliant source, for DataFetcher and IndexFetcher. You can specify the FTP source with the
ftpfetcher option or with the argopy global optionftp. The FTP source support http, ftp or local files protocols. This fetcher is optimised if pyarrow is available, otherwise pandas dataframe are used. See update on Data sources. (#157) by G. Maze
from argopy import IndexFetcher
from argopy import DataFetcher
argo = IndexFetcher(src='gdac')
argo = DataFetcher(src='gdac')
argo = DataFetcher(src='gdac', ftp="https://data-argo.ifremer.fr") # Default and fastest !
argo = DataFetcher(src='gdac', ftp="ftp://ftp.ifremer.fr/ifremer/argo")
with argopy.set_options(src='gdac', ftp='ftp://usgodae.org/pub/outgoing/argo'):
argo = DataFetcher()
Note
The new gdac fetcher uses Argo index to determine which profile files to load. Hence, this fetcher may show poor performances when used with a region access point. Don’t hesitate to check Performances to try to improve performances, otherwise, we recommend to use a webAPI access point (erddap or argovis).
Warning
Since the new gdac fetcher can use a local copy of the GDAC ftp server, the legacy localftp fetcher is now deprecated.
Using it will raise a error up to v0.1.12. It will then be removed in v0.1.13.
New dashboard for profiles and new 3rd party dashboards. Calling on the data fetcher dashboard method will return the Euro-Argo profile page for a single profile. Very useful to look at the data before load. This comes with 2 new utilities functions to get Coriolis ID of profiles (
utilities.get_coriolis_profile_id()) and to return the list of profile webpages (utilities.get_ea_profile_page()). (#198) by G. Maze.
from argopy import DataFetcher as ArgoDataFetcher
ArgoDataFetcher().profile(5904797, 11).dashboard()
from argopy.utilities import get_coriolis_profile_id, get_ea_profile_page
get_coriolis_profile_id([6902755, 6902756], [11, 12])
get_ea_profile_page([6902755, 6902756], [11, 12])
The new profile dashboard can also be accessed with:
import argopy
argopy.dashboard(5904797, 11)
We added the Ocean-OPS (former JCOMMOPS) dashboard for all floats and the BGC-Argo dashboard for BGC floats:
import argopy
argopy.dashboard(5904797, type='ocean-ops')
# or
argopy.dashboard(5904797, 12, type='bgc')
New utility :class:`argopy.utilities.ArgoNVSReferenceTables` to retrieve Argo Reference Tables. (@cc8fdbe) by G. Maze.
from argopy.utilities import ArgoNVSReferenceTables
R = ArgoNVSReferenceTables()
R.all_tbl_name()
R.tbl(3)
R.tbl('R09')
Internals#
from argopy import DataFetcher
argo = DataFetcher(src='gdac').float(6903076)
argo.index
New index store design. A new index store is used by data and index
gdacfetchers to handle access and search in Argo index csv files. It uses pyarrow table if available or pandas dataframe otherwise. More details at Argo Index store. Directly using this index store is not recommended but provides better performances for expert users interested in Argo sampling analysis.
from argopy.stores.argo_index_pa import indexstore_pyarrow as indexstore
idx = indexstore(host="https://data-argo.ifremer.fr", index_file="ar_index_global_prof.txt") # Default
idx.load()
idx.search_lat_lon_tim([-60, -55, 40., 45., '2007-08-01', '2007-09-01'])
idx.N_MATCH # Return number of search results
idx.to_dataframe() # Convert search results to a dataframe
Breaking changes#
Index fetcher for local FTP no longer support the option
index_file. The name of the file index is internally determined using the dataset requested:ar_index_global_prof.txtfords='phy'andargo_synthetic-profile_index.txtfords='bgc'. Using this option will raise a deprecation warning up to v0.1.12 and will then raise an error. (#157) by G. MazeComplete refactoring of the
argopy.plottersmodule intoargopy.plot. (#198) by G. Maze.Remove deprecation warnings for: ‘plotters.plot_dac’, ‘plotters.plot_profilerType’. These now raise an error.
v0.1.10 (4 Mar. 2022)#
Internals#
Update and clean up requirements. Remove upper bound on all dependencies (#182) by R. Abernathey.
v0.1.9 (19 Jan. 2022)#
Features and front-end API#
New method to preprocess data for OWC software. This method can preprocessed Argo data and possibly create float_source/<WMO>.mat files to be used as inputs for OWC implementations in Matlab and Python. See the Salinity calibration documentation page for more. (#142) by G. Maze.
from argopy import DataFetcher as ArgoDataFetcher
ds = ArgoDataFetcher(mode='expert').float(6902766).load().data
ds.argo.create_float_source("float_source")
ds.argo.create_float_source("float_source", force='raw')
ds_source = ds.argo.create_float_source()
This new method comes with others methods and improvements:
A new
Dataset.argo.filter_scalib_pres()method to filter variables according to OWC salinity calibration software requirements,A new
Dataset.argo.groupby_pressure_bins()method to subsample a dataset down to one value by pressure bins (a perfect alternative to interpolation on standard depth levels to precisely avoid interpolation…), see Pressure levels: Group-by bins for more help,An improved
Dataset.argo.filter_qc()method to select which fields to consider (new optionQC_fields),Add conductivity (
CNDC) to the possible output of theTEOS10method.
New dataset properties accessible from the argo xarray accessor:
N_POINTS,N_LEVELS,N_PROF. Note that depending on the format of the dataset (a collection of points or of profiles) these values do or do not take into account NaN. These information are also visible by a simple print of the accessor. (#142) by G. Maze.
from argopy import DataFetcher as ArgoDataFetcher
ds = ArgoDataFetcher(mode='expert').float(6902766).load().data
ds.argo.N_POINTS
ds.argo.N_LEVELS
ds.argo.N_PROF
ds.argo
New plotter function
argopy.plotters.open_sat_altim_report()to insert the CLS Satellite Altimeter Report figure in a notebook cell. (#159) by G. Maze.
from argopy.plotters import open_sat_altim_report
open_sat_altim_report(6902766)
open_sat_altim_report([6902766, 6902772, 6902914])
open_sat_altim_report([6902766, 6902772, 6902914], embed='dropdown') # Default
open_sat_altim_report([6902766, 6902772, 6902914], embed='slide')
open_sat_altim_report([6902766, 6902772, 6902914], embed='list')
open_sat_altim_report([6902766, 6902772, 6902914], embed=None)
from argopy import DataFetcher
from argopy import IndexFetcher
DataFetcher().float([6902745, 6902746]).plot('qc_altimetry')
IndexFetcher().float([6902745, 6902746]).plot('qc_altimetry')
New utility method to retrieve topography. The
argopy.TopoFetcherwill load the GEBCO topography for a given region. (#150) by G. Maze.
from argopy import TopoFetcher
box = [-75, -45, 20, 30]
ds = TopoFetcher(box).to_xarray()
ds = TopoFetcher(box, ds='gebco', stride=[10, 10], cache=True).to_xarray()
For convenience we also added a new property to the data fetcher that return the domain covered by the dataset.
loader = ArgoDataFetcher().float(2901623)
loader.domain # Returns [89.093, 96.036, -0.278, 4.16, 15.0, 2026.0, numpy.datetime64('2010-05-14T03:35:00.000000000'), numpy.datetime64('2013-01-01T01:45:00.000000000')]
Update the documentation with a new section about Data quality control.
Internals#
Uses a new API endpoint for the
argovisdata source when fetching aregion. More on this issue here. (#158) by G. Maze.Update documentation theme, and pages now use the xarray accessor sphinx extension. (#104) by G. Maze.
Update Binder links to work without the deprecated Pangeo-Binder service. (#164) by G. Maze.
v0.1.8 (2 Nov. 2021)#
Features and front-end API#
Improve plotting functions. All functions are now available for both the index and data fetchers. See the Data visualisation page for more details. Reduced plotting dependencies to Matplotlib only. Argopy will use Seaborn and/or Cartopy if available. (#56) by G. Maze.
from argopy import IndexFetcher as ArgoIndexFetcher
from argopy import DataFetcher as ArgoDataFetcher
obj = ArgoIndexFetcher().float([6902766, 6902772, 6902914, 6902746])
# OR
obj = ArgoDataFetcher().float([6902766, 6902772, 6902914, 6902746])
fig, ax = obj.plot()
fig, ax = obj.plot('trajectory')
fig, ax = obj.plot('trajectory', style='white', palette='Set1', figsize=(10,6))
fig, ax = obj.plot('dac')
fig, ax = obj.plot('institution')
fig, ax = obj.plot('profiler')
New methods and properties for data and index fetchers. (#56) by G. Maze. The
argopy.DataFetcher.load()andargopy.IndexFetcher.load()methods internally call on the to_xarray() methods and store results in the fetcher instance. Theargopy.DataFetcher.to_xarray()will trigger a fetch on every call, while theargopy.DataFetcher.load()will not.
from argopy import DataFetcher as ArgoDataFetcher
loader = ArgoDataFetcher().float([6902766, 6902772, 6902914, 6902746])
loader.load()
loader.data
loader.index
loader.to_index()
from argopy import IndexFetcher as ArgoIndexFetcher
indexer = ArgoIndexFetcher().float([6902766, 6902772])
indexer.load()
indexer.index
Add optional speed of sound computation to xarray accessor teos10 method. (#90) by G. Maze.
Code spell fixes (#89) by K. Schwehr.
Internals#
Check validity of access points options (WMO and box) in the facade, no checks at the fetcher level. (#92) by G. Maze.
More general options. Fix #91. (#102) by G. Maze.
trust_envto allow for local environment variables to be used by fsspec to connect to the internet. Useful for those using a proxy.
Documentation on Read The Docs now uses a pip environment and get rid of memory eager conda. (#103) by G. Maze.
xarray.Datasetargopy accessorargohas a clean documentation.
Breaking changes#
Internals#
Internal logging available and upgrade dependencies version support (#56) by G. Maze. To see internal logs, you can set-up your application like this:
import logging
DEBUGFORMATTER = '%(asctime)s [%(levelname)s] [%(name)s] %(filename)s:%(lineno)d: %(message)s'
logging.basicConfig(
level=logging.DEBUG,
format=DEBUGFORMATTER,
datefmt='%m/%d/%Y %I:%M:%S %p',
handlers=[logging.FileHandler("argopy.log", mode='w')]
)
v0.1.7 (4 Jan. 2021)#
Long due release !
Features and front-end API#
Live monitor for the status (availability) of data sources. See documentation page on Status of sources. (#36) by G. Maze.
import argopy
argopy.status()
# or
argopy.status(refresh=15)

Optimise large data fetching with parallelization, for all data fetchers (erddap, localftp and argovis). See documentation page on Parallel data fetching. Two parallel methods are available: multi-threading or multi-processing. (#28) by G. Maze.
from argopy import DataFetcher as ArgoDataFetcher
loader = ArgoDataFetcher(parallel=True)
loader.float([6902766, 6902772, 6902914, 6902746]).to_xarray()
loader.region([-85,-45,10.,20.,0,1000.,'2012-01','2012-02']).to_xarray()
Breaking changes#
In the teos10 xarray accessor, the
standard_nameattribute will now be populated using values from the CF Standard Name table if one exists. The previous values ofstandard_namehave been moved to thelong_nameattribute. (#74) by A. Barna.The unique resource identifier property is now named
urifor all data fetchers, it is always a list of strings.
Internals#
New
open_mfdatasetandopen_mfjsonmethods in Argo stores. These can be used to open, pre-process and concatenate a collection of paths both in sequential or parallel order. (#28) by G. Maze.Unit testing is now done on a controlled conda environment. This allows to more easily identify errors coming from development vs errors due to dependencies update. (#65) by G. Maze.
v0.1.6 (31 Aug. 2020)#
JOSS paper published. You can now cite argopy with a clean reference. (#30) by G. Maze and K. Balem.
Maze G. and Balem K. (2020). argopy: A Python library for Argo ocean data analysis. Journal of Open Source Software, 5(52), 2425 doi: 10.21105/joss.02425.
v0.1.5 (10 July 2020)#
Features and front-end API#
A new data source with the argovis data fetcher, all access points available (#24). By T. Tucker and G. Maze.
from argopy import DataFetcher as ArgoDataFetcher
loader = ArgoDataFetcher(src='argovis')
loader.float(6902746).to_xarray()
loader.profile(6902746, 12).to_xarray()
loader.region([-85,-45,10.,20.,0,1000.,'2012-01','2012-02']).to_xarray()
Easily compute TEOS-10 variables with new argo accessor function teos10. This needs gsw to be installed. (#37) By G. Maze.
from argopy import DataFetcher as ArgoDataFetcher
ds = ArgoDataFetcher().region([-85,-45,10.,20.,0,1000.,'2012-01','2012-02']).to_xarray()
ds = ds.argo.teos10()
ds = ds.argo.teos10(['PV'])
ds_teos10 = ds.argo.teos10(['SA', 'CT'], inplace=False)
argopy can now be installed with conda (#29, #31, #32). By F. Fernandes.
conda install -c conda-forge argopy
Breaking changes#
The
local_ftpoption of thelocalftpdata source must now points to the folder where thedacdirectory is found. This breaks compatibility with rsynced local FTP copy because rsync does not give adacfolder (e.g. #33). An instructive error message is raised to notify users if any of the DAC name is found at the n-1 path level. (#34).
Internals#
Implement a webAPI availability check in unit testing. This allows for more robust
erddapandargovistests that are not only based on internet connectivity only. (@5a46a39).
v0.1.4 (24 June 2020)#
Features and front-end API#
ds = ArgoDataFetcher().region([-85,-45,10.,20.,0,1000.,'2012-01','2012-12']).to_xarray()
ds = ds.argo.point2profile()
ds_interp = ds.argo.interp_std_levels(np.arange(0,900,50))
Insert in a Jupyter notebook cell the Euro-Argo fleet monitoring dashboard page, possibly for a specific float (#20). By G. Maze.
import argopy
argopy.dashboard()
# or
argopy.dashboard(wmo=6902746)
Breaking changes#
[None]
Internals#
Now uses fsspec as file system for caching as well as accessing local and remote files (#19). This closes issues #12, #15 and #17. argopy fetchers must now use (or implement if necessary) one of the internal file systems available in the new module
argopy.stores. By G. Maze.Erddap fetcher now uses netcdf format to retrieve data (#19).
v0.1.3 (15 May 2020)#
Features and front-end API#
from argopy import IndexFetcher as ArgoIndexFetcher
idx = ArgoIndexFetcher().float(6902746)
idx.to_dataframe()
idx.plot('trajectory')
The index fetcher can manage caching and works with both Erddap and localftp data sources. It is basically the same as the data fetcher, but do not load measurements, only meta-data. This can be very useful when looking for regional sampling or trajectories.
Tip
Performance: we recommend to use the localftp data source when working this index fetcher because the erddap data source currently suffers from poor performances. This is linked to #16 and is being addressed by Ifremer.
The index fetcher comes with basic plotting functionalities with the argopy.IndexFetcher.plot() method to rapidly visualise measurement distributions by DAC, latitude/longitude and floats type.
Warning
The design of plotting and visualisation features in argopy is constantly evolving, so this may change in future releases.
The
argopy.DataFetchernow has aargopy.DataFetcher.to_dataframe()method to return apandas.DataFrame.New utilities function:
argopy.utilities.open_etopo1(),argopy.show_versions().
Breaking changes#
The
backendoption in data fetchers and the global optiondatasrchave been renamed tosrc. This makes the code more coherent (@ec6b32e).
Internals#
v0.1.2 (15 May 2020)#
We didn’t like this one this morning, so we move one to the next one !
v0.1.1 (3 Apr. 2020)#
Features and front-end API#
Added new data fetcher backend
localftpin DataFetcher (@c5f7cb6):
from argopy import DataFetcher as ArgoDataFetcher
argo_loader = ArgoDataFetcher(backend='localftp', path_ftp='/data/Argo/ftp_copy')
argo_loader.float(6902746).to_xarray()
Introduced global
OPTIONSto set values for: cache folder, dataset (eg:phy or bgc), local ftp path, data fetcher (erddap or localftp) and user level (standard or expert). Can be used in context with (@83ccfb5):
with argopy.set_options(mode='expert', datasrc='erddap'):
ds = argopy.DataFetcher().float(3901530).to_xarray()
Added a
argopy.tutorialmodule to be able to load sample data for documentation and unit testing (@4af09b5):
ftproot, flist = argopy.tutorial.open_dataset('localftp')
txtfile = argopy.tutorial.open_dataset('weekly_index_prof')
Improved xarray argo accessor. Added methods for casting data types, to filter variables according to data mode, to filter variables according to quality flags. Useful methods to transform collection of points into collection of profiles, and vice versa (@14cda55):
ds = argopy.DataFetcher().float(3901530).to_xarray() # get a collection of points
dsprof = ds.argo.point2profile() # transform to profiles
ds = dsprof.argo.profile2point() # transform to points
Changed License from MIT to Apache (@25f90c9)
Internal machinery
Add
__all__to controlfrom argopy import *(@83ccfb5)All data fetchers inherit from class
ArgoDataFetcherProtoinproto.py(@44f45a5)Data fetchers use default options from global OPTIONS
In Erddap fetcher: methods to cast data type, to filter by data mode and by QC flags are now delegated to the xarray argo accessor methods.
Data fetchers methods to filter variables according to user mode are using variable lists defined in utilities.
argopy.utilitiesaugmented with listing functions of: backends, standard variables and multiprofile files variables.Introduce custom errors in errors.py (@2563c9f)
Front-end API ArgoDataFetcher uses a more general way of auto-discovering fetcher backend and their access points. Turned of the
deploymentsaccess point, waiting for the index fetcher to do that.Improved xarray argo accessor. More reliable
point2profileand data type casting withcast_type
Internals#
v0.1.0 (17 Mar. 2020)#
Initial release.
Erddap data fetcher